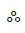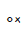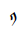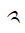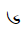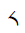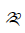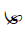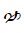Tibetan Unicode Block
The Unicode Tibetan block is a dedicated section within the Unicode Standard, a standardized character encoding system for digital representation of text from various writing systems around the world. This block, officially named "Tibetan" in Unicode, is assigned the code range U+0F00 to U+0FFF and is primarily used for encoding Tibetan script characters. Tibetan script is an abugida writing system used primarily to write the Tibetan language. It is also employed for other languages in the Tibetan cultural sphere, such as Dzongkha and Ladakhi. The Unicode Tibetan block includes a comprehensive range of characters, combining consonants, vowels, diacritics, and other marks necessary for accurately representing Tibetan text. The encoding of Tibetan script in Unicode has been essential for digital communication, text processing, and font development, making it possible to represent Tibetan text on computers, the internet, and various digital platforms. This block ensures the preservation and accessibility of Tibetan language and culture in the digital age.
View a range of fonts that support the Tibetan block.
Below you will find all the characters that are in the Tibetan unicode block. Currently there are 211 characters in this block.